Recent Posts
BIMI Certificates and Domains
- steve
- May 29, 2026
BIMI is the protocol that gives you little images and blue checkmarks alongside your message in the inboxes of some mail clients.
Read MoreThe new DMARC is here
- steve
- May 20, 2026
DMARCbis the new DMARC is finally here.
- RFC 9989 - Domain-Based Message Authentication, Reporting, and Conformance (DMARC)
- RFC 9990 - Domain-Based Message Authentication, Reporting, and Conformance (DMARC) Aggregate Reporting
- RFC 9991 - Domain-Based Message Authentication, Reporting, and Conformance (DMARC) Failure Reporting
It’s not DMARCbis any more, it’s just DMARC.
Read MoreDKIM2, Asynchronous Bounces and VERP
- steve
- Apr 27, 2026
This is just expanding on some of the points Laura made last week.
Read MoreDKIM2: What it means for the future of email
- laura
- Apr 23, 2026
Table of Contents
- Introduction
- What is it?
- OK, but really, what is it?
- OK. Why?
- Current Status
- ESPs Take Note
- Next Steps
- Conclusion
Introduction
After years of stagnation in email authentication protocol development we have a new player entering town. The protocol is DKIM2 and it’s in active development over at the IETF. If you want to see the sausage being made, you can visit the IETF datatracker to see the details and sign up for the mailing list.
Read MoreThe spam folder and opens
- laura
- Apr 9, 2026

There’s a post getting a lot of traction in my LinkedIn feed from someone spreading misinformation about open rates. A bunch of deliverability colleagues have weighed in and pointed out some of the mistakes, but there’s one very big mis-statement I haven’t seen anyone correct. [1]
Read MoreSPF ?all
- steve
- Mar 20, 2026

I was updating my SPF library and discovered that the example code snippets didn’t work any more, as at some point in 2024 AOL switched their SPF record from “(lots of stuff]) ~all” to “(lots of stuff) ?all”. Nothing particularly surprising, folks change their setups occasionally. I updated the example code to expect a neutral response rather than softfail and all the tests pass.
Upcoming webinar on Gmail and inbox signals
- laura
- Mar 13, 2026
I’m thrilled to announce I’m sitting down at the beginning of April to talk about inboxing in 2026.
Read MoreRecent Writings and Events
- laura
- Feb 19, 2026
I don’t know about you, but we’re more than 6 weeks into 2026 and I can’t figure out where all the time has gone. It’s been a much busier January than I’m used to. I’ve been working on a lot, including a project I’ve been trying to get off the ground for a while. I’m really excited it’s finally taking shape and I hope to be able to share it with folks in the next month or so.
Read MoreNot Business as Usual
- laura
- Jan 26, 2026
I don’t know what to say about what’s happening in the US, but I know I can’t stay silent, either. I don’t have anything inspiring to say here. I just cannot keep silent and pretend it’s all business as usual. I’m saddened, I’m horrified, I’m sick about what the government of the US is doing to citizens and non-citizens alike.
Read MoreDon't send customer-generated content
- steve
- Jan 19, 2026
I just got this email:
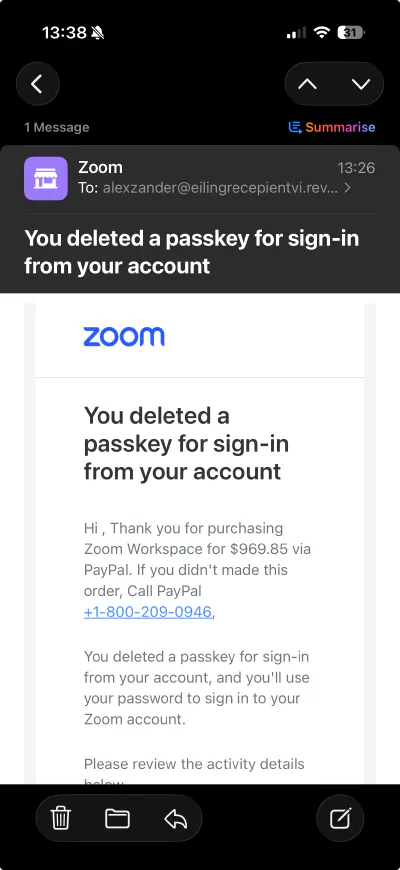
SPF is valid. It passes DKIM for zoom.us.
Read MoreCategories
Tags
- 2010
- 2016
- 2fa
- 419
- 4xx
- 554
- 5xx
- @
- Aarp
- Abacus
- Abandoned
- Aboutmyemail
- Abuse
- Abuse Desk
- Abuse Enforcement
- Abuse Prevention
- Academia
- Accreditation
- Acme
- Acquisition
- Address Book
- Addresses
- Administrivia
- Adsp
- Advanced Delivery
- Advertiser
- Advertising
- Advice
- Affiliate
- Affiliates
- After the Email
- Alerts
- Algorithm
- Alice
- Alignment
- Allcaps
- Alt Text
- AMA
- Amazon
- Amp
- Amsterdam
- Analysis
- Anecdotes
- Anti-Spam
- Anti-Spam Laws
- Anti-Spammers
- Antwort
- AOL
- Appeals
- Appearances
- Appending
- Apple
- Arc
- Arf
- Arrest
- Arrests
- Ascii
- Asides
- Ask Laura
- Askwttw
- Assertion
- Assumptions
- ATT
- Attacks
- Attention
- Attrition
- Audit
- Authentication
- Authentication. BT
- Autonomous
- Award
- B2B
- B2C
- Backhoe
- Backscatter
- Backus-Naur Form
- Banks
- Barracuda
- Barry
- Base64
- Base85
- Bcc
- Bcp
- Bear
- Bears
- Behaviour
- Benchmark
- BESS
- Best Practices
- Bgp
- BIMI
- Bit Rot
- Bitly
- Bizanga
- Black Friday
- Blackfriday
- Blacklist
- Blacklists
- Blast
- Blo
- Block
- Blockin
- Blocking
- Blocklist
- Blocklisting
- Blocklists
- Blocks
- Blog
- Blog Links
- Blogroll
- Blogs
- Bob
- Boca
- Bofa
- Book Review
- Bot
- Botnet
- Botnets
- Bots
- Bounce
- Bounce Handling
- Bounces
- Branding
- Brands
- Breach
- Breaches
- Breech
- Bronto
- Browser
- Bsi
- Bucket
- Bulk
- Bulk Folder
- Bulk Mail
- Business
- Business Filters
- Buying Leads
- Buying Lists
- C-28
- CA
- Caa
- Cabbage
- Cache
- Cadence
- CAH
- California
- Campaign
- CAN SPAM
- Canada
- Candy
- Candycandycandy
- Canonicalization
- Canspam
- Captcha
- Career Developmnent
- Careers at WttW
- Cargo Cult
- Case Law
- Cases
- CASL
- Cat
- Cbl
- CDA
- Cert
- Certificates
- Certification
- CFL
- CFWS
- Change
- Charter
- Cheat
- Cheese
- Choicepoint
- Choochoo
- Christmas
- Chrome
- Cidr
- Cisco
- Civil
- Clear.net
- Clearwire.net
- Cli
- Click
- Click Through
- Click Tracking
- Clicks
- Clickthrough
- Client
- Cloudflare
- Cloudmark
- Cname
- Co-Reg
- Co-Registration
- Cocktail
- Code
- COI
- Comcast
- Comments
- Commercial
- Communication
- Community
- Comodo
- Comparison
- Competitor
- Complaint
- Complaint Rates
- Complaints
- Compliance
- Compromise
- Conference
- Conferences
- Confirmation
- Confirmed (Double) Opt-In
- Confirmed Opt-In
- Congress
- Consent
- Conservatives
- Consistency
- Constant Contact
- Consultants
- Consulting
- Content
- Content Filters
- Contracts
- Cookie
- Cookie Monster
- COPL
- Corporate
- Cost
- Court Ruling
- Cox
- Cox.net
- Cpanel
- Crib
- Crime
- CRM
- Crowdsource
- Crtc
- Cryptography
- CSRIC
- CSS
- Curl
- Customer
- Cyber Monday
- Czar
- Data
- Data Hygiene
- Data Security
- Data Segmentation
- Data Verification
- DBL
- Dbp
- Ddos
- Dea
- Dead Addresses
- Dedicated
- Dedicated IPs
- Defamation
- Deferral
- Definitions
- Delays
- Delisting
- Deliverability
- Deliverability Experts
- Deliverability Improvement
- Deliverability Summit
- Deliverability Week
- Deliverability Week 2024
- Deliverabiltiy
- DeliverabiltyWeek
- Delivery Blog Carnival
- Delivery Discussion
- Delivery Emergency
- Delivery Experts
- Delivery Improvement
- Delivery Lore
- Delivery News
- Delivery Problems
- Dell
- Design
- Desks
- Dhs
- Diagnosis
- Diff
- Dig
- Direct Mag
- Direct Mail
- Directives
- Discounts
- Discovery
- Discussion Question
- Disposable
- Dk
- Dkim
- Dkim2
- Dkimcore
- DMA
- DMARC
- DMARCbis
- DNS
- Dnsbl
- Dnssec
- Docs
- Doingitright
- Domain
- Domain Keys
- Domain Reputation
- DomainKeys
- Domains
- Domains by Proxy
- Dontpanic
- Dot Stuffing
- Dotcom
- Double Opt-In
- Dublin
- Dyn
- Dynamic Email
- E360
- Earthlink
- Ec2
- Ecoa
- Economics
- ECPA
- Edatasource
- Edns0
- Eec
- Efail
- Efax
- Eff
- Election
- Email Address
- Email Addresses
- Email Change of Address
- Email Client
- Email Design
- Email Formats
- Email Marketing
- Email Strategy
- Email Verification
- Emailappenders
- Emailgeeks
- Emails
- Emailstuff
- Emoji
- Emoticon
- Encert
- Encryption
- End User
- Endusers
- Enforcement
- Engagement
- Enhanced Status Code
- Ennui
- Entrust
- Eol
- EOP
- Epsilon
- Esp
- ESPC
- ESPs
- EU
- Ev Ssl
- Evaluating
- Events
- EWL
- Exchange
- Excite
- Expectations
- Experience
- Expires
- Expiring
- False Positives
- FAQ
- Fathers Day
- Fbl
- FBL Microsoft
- FBLs
- Fbox
- FCC
- Fcrdns
- Featured
- Fedex
- Feds
- Feedback
- Feedback Loop
- Feedback Loops
- Fiction
- Filter
- Filter Evasion
- Filtering
- Filterings
- Filters
- Fingerprinting
- Firefox3
- First Amendment
- FISA
- Flag Day
- Forensics
- Format
- Formatting
- Forms
- Forwarding
- Fraud
- Freddy
- Frequency
- Friday
- Friday Spam
- Friendly From
- From
- From Address
- FTC
- Fussp
- Gabbard
- GDPR
- Geoip
- Gevalia
- Gfi
- Git
- Giveaway
- Giving Up
- Global Delivery
- Glossary
- Glyph
- Gmail
- Gmails
- Go
- Godaddy
- Godzilla
- Good Email Practices
- Good Emails in the Wild
- Goodmail
- Google Buzz
- Google Postmaster Tools
- Graphic
- GreenArrow
- Greylisting
- Greymail
- Groupon
- GT&U
- Guarantee
- Guest Post
- Guide
- Habeas
- Hack
- Hacking
- Hacks
- Hall of Shame
- Harassment
- Hard Bounce
- Harvesting
- Harvey
- Hash
- Hashbusters
- Headers
- Heartbleed
- Hearts
- HELO
- Help
- Henet
- Highspeedinternet
- Hijack
- History
- Holiday
- Holidays
- Holomaxx
- Hostdns4u
- Hostile
- Hostname
- Hotmail
- How To
- Howto
- Hrc
- Hsts
- HTML
- HTML Email
- Http
- Huey
- Humanity
- Humor
- Humour
- Hygiene
- Hypertouch
- I18n
- ICANN
- Icloud
- IContact
- Identity
- Idiots
- Idn
- Ietf
- Image Blocking
- Images
- Imap
- Inbox
- Inbox Delivery
- Inboxing
- Index
- India
- Indiegogo
- Industry
- Infection
- Infographic
- Information
- Inky
- Inline
- Innovation
- Insight2015
- Integration
- Internationalization
- Internet
- Intuit
- IP
- IP Address
- Ip Addresses
- IP Repuation
- IP Reputation
- IPhone
- IPO
- IPv4
- IPv6
- Ironport
- Ironport Cisco
- ISIPP
- ISP
- ISPs
- J.D. Falk Award
- Jail
- Jaynes
- JD
- Jobs
- Json
- Junk
- Juno/Netzero/UOL
- Key Rotation
- Keybase
- Keynote
- Kickstarter
- Kraft
- Laposte
- Lavabit
- Law
- Laws
- Lawsuit
- Lawsuits
- Lawyer
- Layout
- Lead Gen
- Leak
- Leaking
- Leaks
- Legal
- Legality
- Legitimate Email Marketer
- Letsencrypt
- Letstalk
- Linked In
- Links
- List Hygiene
- List Management
- List Purchases
- List the World
- List Usage
- List-Unsubscribe
- Listing
- Listmus
- Lists
- Litmus
- Live
- Livingsocial
- London
- Lookup
- Lorem Ipsum
- Lycos
- Lyris
- M3AAWG
- Maawg
- MAAWG2007
- Maawg2008
- MAAWG2012
- MAAWGSF
- Machine Learning
- Magill
- Magilla
- Mail Chimp
- Mail Client
- MAIL FROM
- Mail Privacy Protection
- Mail Problems
- Mail.app
- Mail.ru
- Mailboxes
- Mailchimp
- Mailgun
- Mailing Lists
- Mailman
- Mailop
- Mainsleaze
- Maitai
- Malicious
- Malicious Mail
- Malware
- Mandrill
- Maps
- Marketer
- Marketers
- Marketing
- Marketo
- Markters
- Maths
- Mcafee
- Mccain
- Me@privacy.net
- Measurements
- Media
- Meh
- Meltdown
- Meme
- Mentor
- Merry
- Message-ID
- Messagelabs
- MessageSystems
- Meta
- Metric
- Metrics
- Micdrop
- Microsoft
- Milter
- Mime
- Minimal
- Minshare
- Minute
- Mit
- Mitm
- Mobile
- Models
- Monitoring
- Monkey
- Monthly Review
- Mpp
- MSN/Hotmail
- MSN/Hotmail
- MTA
- Mua
- Mutt
- Mx
- Myths
- Myvzw
- Needs Work
- Netcat
- Netsol
- Netsuite
- Network
- Networking
- New Year
- News
- News Articles
- Nhi
- NJABL
- Now Hiring
- NTP
- Nxdomain
- Oath
- Obituary
- Office 365
- Office365
- One-Click
- Only Influencers
- Oops
- Opaque Cookie
- Open
- Open Detection
- Open Rate
- Open Rates
- Open Relay
- Open Tracking
- Opendkim
- Opens
- Openssl
- Opt-In
- Opt-Out
- Optonline
- Oracle
- Outage
- Outages
- Outblaze
- Outlook
- Outlook.com
- Outrage
- Outreach
- Outsource
- Ownership
- Owning the Channel
- P=reject
- Pacer
- Pander
- Panel
- Password
- Patent
- Paypal
- PBL
- Penkava
- Permission
- Personalities
- Personalization
- Personalized
- Pgp
- Phi
- Philosophy
- Phish
- Phishers
- Phishing
- Phising
- Photos
- Pii
- PIPA
- PivotalVeracity
- Pix
- Pluscachange
- Podcast
- Policies
- Policy
- Political Mail
- Political Spam
- Politics
- Porn
- Port25 Blocking
- Postfix
- Postmaster
- Power MTA
- Practices
- Predictions
- Preferences
- Prefetch
- Preview
- Primers
- Privacy
- Privacy Policy
- Privacy Protection
- Private Relay
- Productive Mail
- Promotions
- Promotions Tab
- Proofpoint
- Prospect
- Prospecting
- Protocols
- Proxy
- Psa
- PTR
- Public Suffix List
- Purchased
- Purchased Lists
- Purchases
- Purchasing Lists
- Questions
- Quoted Printable
- Rakuten
- Ralsky
- Rant
- Rate Limiting
- Ray Tomlinson
- Rc4
- RDNS
- Re-Engagement
- Read
- Ready to Post
- Readytopost
- Real People
- Realtime Address Verification
- Recaptcha
- Received
- Receivers
- Recipient
- Recipients
- Redirect
- Redsnapper
- Reference
- Registrar
- Registration
- Rejection
- Rejections
- Rejective
- Relationship
- Relevance
- Relevancy
- Removals
- Render Rate
- Rendering
- Replay
- Repost
- Repudiation
- Reputation
- Requirements
- Research
- Resources
- Responsive
- Responsive Design
- Responsys
- Retail
- Retired Domains
- Retro
- Return Path
- Return Path Certified
- ReturnPath
- Reunion.com
- Reverse Dns
- RFC
- RFC2047
- RFC2821/2822
- RFC5321/5322
- RFC5322
- RFC8058
- RFC821/822
- RFCs
- Roadr
- RoadRunner
- Rodney Joffe
- ROKSO
- Role Accounts
- Rollout
- RPost
- RPZ
- Rule 34
- Rules
- Rum
- Rustock
- S.1618
- SaaS
- Sales
- Salesforce
- Sass
- SBCGlobal
- Sbl
- Scam
- Scammers
- Scams
- Scanning
- Scraping
- Screamer
- Screening
- Script
- Sec
- Secure
- Security
- Segmentation
- Selligent
- Send
- Sender
- Sender Score
- Sender Score Certified
- Senderbase
- Senderid
- Senders
- Senderscore
- Sendgrid
- Sending
- Sendy
- Seo
- Service
- Services
- Ses
- Seth Godin
- SFDC
- SFMAAWG2009
- SFMAAWG2010
- SFMAAWG2014
- Shared
- Shell
- Shouting
- Shovel
- Signing
- Signups
- Silly
- Single Opt-In
- Slack
- Slicing
- Smarthost
- Smiley
- Smime
- SMS
- SMTP
- Snds
- Snowshoe
- Soa
- Socia
- Social Media
- Social Networking
- Soft Bounce
- Software
- Sony
- SOPA
- Sorbs
- Spam
- Spam Blocking
- Spam Definition
- Spam Filtering
- Spam Filters
- Spam Folder
- Spam Law
- Spam Laws
- Spam Reports
- Spam Traps
- Spam. IMessage
- Spamarrest
- Spamassassin
- Spamblocking
- Spamcannibal
- Spamcon
- Spamcop
- Spamfiltering
- Spamfilters
- Spamfolder
- Spamhaus
- Spamhause
- Spammer
- Spammers
- Spammest
- Spamming
- Spamneverstops
- Spamresource
- Spamtrap
- Spamtraps
- Spamza
- Sparkpost
- Speaking
- Special Offers
- Spectre
- SPF
- Spoofing
- SproutDNS
- Ssl
- Standards
- Stanford
- Starttls
- Startup
- State Spam Laws
- Statistics
- Storm
- Strategy
- Stripo
- Stunt
- Subject
- Subject Lines
- Subscribe
- Subscriber
- Subscribers
- Subscription
- Subscription Process
- Success Stories
- Suing
- Suppression
- Surbl
- Sureclick
- Suretymail
- Survey
- Swaks
- Syle
- Symantec
- Tabbed Inbox
- Tabs
- Tagged
- Tagging
- Target
- Targeting
- Techincal
- Technical
- Telnet
- Template
- Tempo
- Temporary
- Temporary Failures
- Terminology
- Testing
- Text
- Thanks
- This Is Spam
- Throttling
- Time
- Timely
- TINS
- TLD
- Tlp
- TLS
- TMIE
- Tmobile
- Too Much Mail
- Tool
- Tools
- Toomuchemail
- Tor
- Trademark
- Traffic Light Protocol
- Tragedy of the Commons
- Transactional
- Transition
- Transparency
- Traps
- Travel
- Trend/MAPS
- Trend Micro
- Trend/MAPS
- Trigger
- Triggered
- Troubleshooting
- Trustedsource
- TWSD
- Txt
- Types of Email
- Typo
- Uce
- UCEprotect
- Unblocking
- Uncategorized
- Undisclosed Recipients
- Unexpected Email
- Unicode
- Unroll.me
- Unsolicited
- Unsubcribe
- Unsubscribe
- Unsubscribed
- Unsubscribes
- Unsubscribing
- Unsubscription
- Unwanted
- URIBL
- Url
- Url Shorteners
- Usenet
- User Education
- Utf8
- Valentine's Day
- Validation
- Validity
- Value
- Valueclick
- Verification
- Verizon
- Verizon Media
- VERP
- Verticalresponse
- Vetting
- Via
- Video
- Violence
- Virginia
- Virtumundo
- Virus
- Viruses
- Vmc
- Vocabulary
- Vodafone
- Volume
- Vzbv
- Wanted Mail
- Warmup
- Weasel
- Webinar
- Webmail
- Weekend Effect
- Welcome Emails
- White Space
- Whitelisting
- Whois
- Wiki
- Wildcard
- Wireless
- Wiretapping
- Wisewednesday
- Women of Email
- Woof
- Woot
- Wow
- Wtf
- Wttw in the Wild
- Xbl
- Xfinity
- Xkcd
- Yahoo
- Yahoogle
- Yogurt
- Zoidberg
- Zombie
- Zombies
- Zoominfo
- Zurb